Chapter 6: Markov Chain Monte Carlo
Introduction to Markov chains
Markov chain Monte Carlo (Markov Chain simulation or MCMC for short) is a Bayesian way of finding values of \(\theta\) from an approximate distribution, where \(\theta\) are the unknown parameters that make up the distribution. The Markov chain algorithm corrects this approximate distribution in each iteration, eventually converging to a final distribution that aligns with the posterior distribution \(p(\theta|y)\) (for more on the posterior distribution, see Chapter 4). This is particularly useful when the posterior is difficult or impossible to sample making MCMC a powerful tool. This converging of the distribution is where the power of Markov chain simulations lies, allowing for the determination of the original distribution solely from its data.
This is done by constructing a stationary Markov chain, a sequence of random variables, \(\theta_t\), where \(\theta_t\) has the same distribution as the posterior. Now instead of taking independent variables, the Markov chain introduces variables \(\theta_{\{1, ..., T\}}\) obeying the Markov property
such that the variable \(\theta_{t+1}\) is only dependent on the most recent variable \(\theta_{t}\) and therefore, the distribution of \(\theta_{t+1}\) does not depend on how the chain got to \(\theta_{t}\), but only what this state is. In other words, one could say that “What comes next is determined entirely by the present situation.”
Markov chain simulations are frequently used when it is inefficient to find \(\theta\) directly from the posterior \(p(\theta|y).\) As mentioned before, we sample a new, random \(\theta\) iteratively, with the expectation that the distribution converges more and more to \(p(\theta|y).\) Generally, MCMC is exceptionally effective for high-dimensional distributions, as direct-sampling Monte Carlo methods cannot complete such analysis in a reasonable time.
MCMC algorithms, such as Metropolis-Hasting and affine parameters, propose and accept new steps of the MCMC chain in the parameter space, allowing the chain to explore the parameter space.
Explanation of Metropolis-Hasting
The simplest method of simulating a Markov chain is the Metropolis-Hastings algorithm, which itself relies on the more basic Metropolis algorithm. This we will inquire about first.
The Metropolis algorithm expands on a random walk, a process where each step is determined randomly based on the current position, with a rule that accepts or rejects the sampled data to converge the sampled data to the specified target distribution. This accepting and rejecting is based on a given rule. The algorithm works as follows:
Draw a starting point \(\theta_0\) with \(p(\theta_0|y) > 0\) from a certain starting distribution \(p_0(\theta)\). For example, \(p_0(\theta) \sim \mathcal{N}(\theta_{t-1}, \sigma^2)\) if \(\theta \in \mathbb{R}\).
For \(t = 1, 2, \ldots\):
Sample a proposal \(\theta_\ast\) from a proposal distribution \(J_t(\theta_\ast|\theta_{t-1})\) at time \(t\). We require \(J_t(\theta_a|\theta_b) = J_t(\theta_b|\theta_a)\) for all \(\theta_a\), \(\theta_b\), and \(t\) for now.
Calculate the ratio of the densities of \(\theta_a\) and \(\theta_b\):
\[r = \frac{p(\theta_a|y)}{p(\theta_b|y)} = \frac{p(\theta_{\ast}|y)}{p(\theta_{t-1}|y)}.\]Set
\[\begin{split}\theta_t = \begin{cases} \theta_\ast &\ \text{if } u \text{ } \leq \min(r, 1), \text{where } u \sim \text{Uniform(0,1)} \\ \theta_{t-1} &\ \text{otherwise}. \end{cases}\end{split}\]
To put this into words; a value of \(\theta_*\) is sampled from a previous distribution, and if the ratio of densities \(r\) is lower than a random uniform variable, the proposed state is rejected and \(\theta_t\) = \(\theta_{t-1}\).
Now we return to the Metropolis-Hastings (MH) algorithm. In contrast to the Metropolis algorithm, the MH algorithm does not require \(J_t(\theta_*|\theta_{t-1})\) to be symmetric. Due to this new, asymmetric proposal distribution, we must alter the ratio of densities of \(\theta_a\) and \(\theta_b\), which is as follows:
For the proposal distribution, the following characteristics are favorable. First, it is easy to sample from \(J(\theta_\ast| \theta)\) for any \(\theta\). Second, the ratio of \(r\) (as given by the above equation) is easy to calculate. Third, the random walk does not go too slowly, i.e., the sampled values are not too close together. Finally, rejected jumps do not happen often, as they hurt the performance of the algorithm.
The acceptance rate of the MH algorithm is the proportion of the steps that are accepted. A good MH algorithm has in general an acceptance rate of 0.44. When the acceptance rate is too high (e.g, >70%), the MH algorithm is likely taking very small steps resulting in a slow exploration of parameter space. When the acceptance rate is too low (e.g, <10%), the MH algorithm is rejecting too many steps, making it inefficient.
Burn-in Time and Autocorrelation
In the Metropolis-Hastings algorithm, the chain takes some steps to reach a stable value, called the burn-in time. We discard these points before we make the probability distribution. In a one-parameter fit, this can easily be done by eye. However, in fits with many parameters, you would prefer an automated process to take care of this. This can be done via autocorrelation. If we have the chain \(\{X_1, X_2,...,X_n\}\) we can calculate the autocorrelation coefficient with
where \(k\) is the lag or time gap between the samples and \(\mu\) the mean. We can choose a threshold value, say 0.1, and calculate above which value of \(k\) the autocorrelation coefficient is below the threshold. We can then take \(\{X_k,...,X_n\}\) to be samples from our posterior distribution. In the example below we will use autocorrelation to determine the burn-in time.
1D Example
We have collected data and want to infer the mean and its error. The data points are \(y_i=\)[1,2,3] with error \(\sigma_{y_i}=\)[1,1,1]. We can do this analytically and find \(\mu=2\) and \(\sigma_\mu=1/\sqrt{3}\approx0.577\). We want to derive these values using the Metropolis-Hasting algorithm. First, we need to construct the posterior. We will assume a flat prior making the posterior the likelihood. Next, we pick a starting point for the Markov chain. Using this as the center of a normal distribution, a new point is drawn from the distribution. We find the ratio of the new points posterior to the last point. If the ratio is larger than a random value between 0 and 1, we accept the new point to the chain. Otherwise, the last point value is added to the chain. These steps are repeated until we can reconstruct the desired distribution for \(\mu\). We take 10 as the starting point and use a starting distribution with a scale parameter of 3. This allows the chain to converge to the correct value quickly.
As mentioned before, the chain takes some steps to get to a stable value. We disregard these points before we make the probability distribution.
[1]:
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import norm
steps = 10000
X = 10
Xs = []
y = np.array([1, 2, 3])
y_sigma = np.array([1, 1, 1])
def prob_dist(mu):
return np.exp(-1 * np.sum(((y - mu) ** 2 / (2 * y_sigma ** 2))))
def autocorrelation(chain, lag):
sum = np.sum((chain[:len(chain) - lag] - np.mean(chain)) * (chain[lag:] - np.mean(chain)))
normalization = (len(chain) - lag) * np.var(chain)
autocorr = sum / normalization
return autocorr
for _ in range(steps):
Y = np.random.normal(X, 1)
q = prob_dist(Y) / prob_dist(X)
if q >= np.random.rand():
X = Y
Xs.append(X)
auto = np.inf
index = 1
while auto >= 0.01:
auto = autocorrelation(Xs, index)
index += 1
if index >= len(Xs):
print('autocorrelation failed')
break
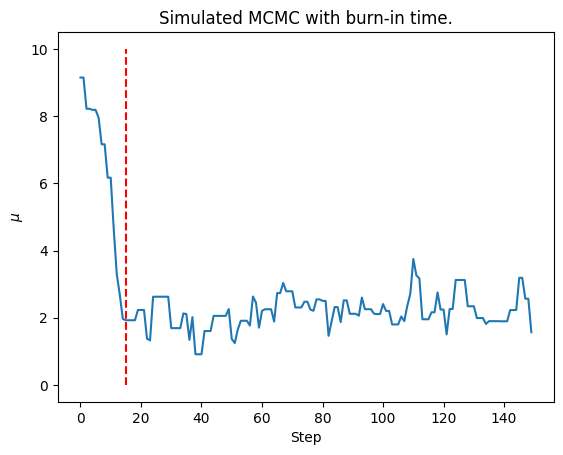
print(f'The burn-in time is at step {index}.')
plt.figure()
plt.plot(Xs[:10 * index])
plt.vlines(index, 0, 10, colors='red', linestyles='dashed')
plt.xlabel('Step')
plt.ylabel(r'$\mu$')
plt.title('Simulated MCMC with burn-in time.')
plt.show()
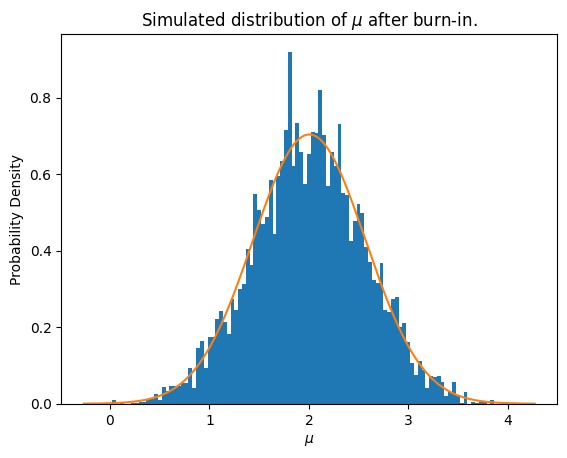
plt.figure()
plt.hist(Xs[index:], bins=steps // 100, density=True)
mu = np.mean(Xs[index:])
mu_sigma = np.std(Xs[index:])
print(f'Simulated mean: {mu:.3f}, True mean: 2')
print(f'Simulated error: {mu_sigma:.3f}, True error: 0.577')
x = np.linspace(mu - 4 * mu_sigma, mu + 4 * mu_sigma, 1000)
plt.plot(x, norm.pdf(x, mu, mu_sigma))
plt.xlabel(r'$\mu$')
plt.ylabel('Probability Density')
plt.title(r'Simulated distribution of $\mu$ after burn-in.')
plt.show()
The burn-in time is at step 15.
Simulated mean: 2.004, True mean: 2
Simulated error: 0.567, True error: 0.577
We want to compare the results of the MCMC with Least Squares (LS), see Chapter 1. By implementing a simple LS program, we can find the best-fitting \(\,\mu\) and the 68% confidence interval.
[2]:
y = np.array([1, 2, 3])
y_sigma = np.array([1, 1, 1])
def chi_2(mu):
return np.sum((y - mu[:, None]) ** 2 / (y_sigma ** 2), axis=1)
mu_list = np.linspace(0, 4, 1000000)
chi_2_list = chi_2(mu_list)
min_chi_2 = min(chi_2_list)
mu_fit = [x for x, y in zip(mu_list, chi_2_list) if y == min_chi_2][0]
lower_bound = np.interp(-1 * (min_chi_2 + 1), -1 * chi_2_list[mu_list <= mu_fit], mu_list[mu_list <= mu_fit])
upper_bound = np.interp(min_chi_2 + 1, chi_2_list[mu_list >= mu_fit], mu_list[mu_list >= mu_fit])
plt.plot(mu_list, chi_2(mu_list), label=r'$\chi^2(\mu)$')
plt.axhline(y=min_chi_2 + 1, color='red', linestyle='--', label='68% Confidence Level')
plt.xlabel(r'$\mu$')
plt.ylabel(r'$\chi^2$')
plt.legend()
plt.show()
print(f'Calculated mean from LS: {mu_fit:.3f}±{(upper_bound - lower_bound) / 2:.3f}')
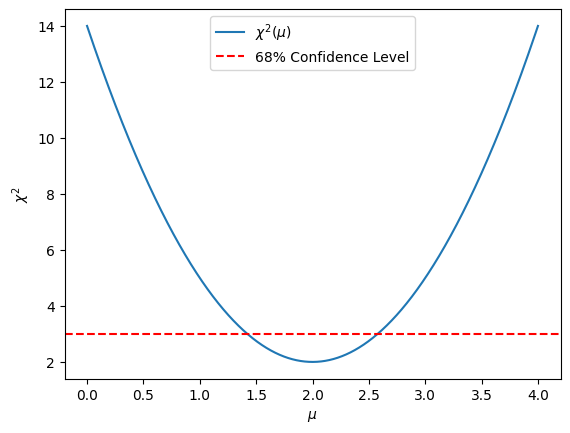
Calculated mean from LS: 2.000±0.577
The results match those obtained using both the analytical solution and the MCMC algorithm. For this simple problem, the LS method is significantly faster than MCMC. However, MCMC is typically more effective than LS for complex or nonlinear models, non-Gaussian errors, multimodal distributions, or when prior knowledge needs to be included. In contrast, LS is quicker and easier for linear models with Gaussian errors but falls short when dealing with more complicated scenarios.
Explanation of affine-invariant algorithms (used in emcee)
Affine invariance
While the Metropolis-Hasting implementation may be particularly useful for some distributions, it fails for badly scaled or highly skewed distributions. In 2010, Goodman and Weare suggested the use of affine invariant many particle MCMC samplers, where they make use of affine transformations of the form
Furthermore, if a sample \(X\) has probability density \(p(x)\), then the affine transformed \(Y = AX + b\) has probability density \(p(y) = p(Ax+b) \propto p(x)\).
Rescaling the distribution allows for easier computations with less customization. For example, the Metropolis MCMC application would have difficulty analyzing an anisotropic density like
as it will have to take small steps of the order of \(\sqrt{a}\) in all directions due to its anisotropic nature. Ideally, it would like to take bigger steps in the stretched out direction to increase the efficiency, but it is limited by these small steps. This results in a long burn-in time until the Markov chain reaches equilibrium.
However, using the suited affine transformation
we can alter this problem into a well-scaled case
Where \(p(y)\) is much easier to sample than the initial probability density of \(p(x)\).
For an affine invariant algorithm, the two cases of \(p(x)\) and \(p(y)\) are the same and equally difficult, such that it does not depend on the parameter \(a\) that determines the aspect ratio of the distribution.
|
|
|---|---|
Figure 6.1: Skewed data set given in Eq. 6.2. |
Figure 6.2: Transformed data set given in Eq. 6.3. |
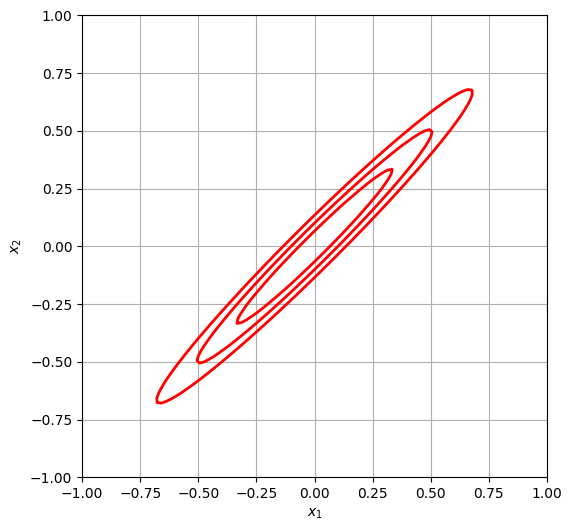
Let us create two Monte Carlo runs with an identical sequence of independent identically distributed variables and we use the two densities \(p(x)\) and \(p(y)\). If our algorithm is affine invariant, it must obey that \(Y(t) = AX(t) + b\) (given initial points \(X(0)\) for \(p(x)\) and \(Y(0) = AX(0) + b\) for \(p(y)\)).
Stretch Move
Instead of using a single chain of walkers, affine-invariant algorithms use an ensemble of walkers. In this case, the updated position of each walker is based on the current position of the other walkers in the ensemble. When using an ensemble of \(K\) walkers \(S = \{X_k\}\), the position is updated by drawing a random walker from the complementary space \(S_{[k]} = \{X_j, \forall j \neq k\}\)
Then a new position is proposed as follows:
where \(Z\) is a randomly chosen scaling factor from the distribution \(g(z)\). Typically, it is proposed that:
This implementation of the invariant algorithm is informally called the ‘’stretch move’’. The autocorrelation time for this method is much shorter than that of typical MCMC methods like the Metropolis-Hastings algorithm.
The parallel stretch move
Whilst using the stretch move is much more efficient than simpler algorithms like Metropolis-Hastings, the walkers are updated in series, one after another. If we could evolve them all in parallel this may significantly improve the autocorrelation time.
This is not entirely feasible in EMCEE as this would violate detailed balance. Detailed balance ensures that the chain is reversible, allowing for sampling from the correct target distribution. However, an alternative is to split our ensemble of \(K\) walkers \(S = \{X_k\}\) into two subsets \(S^{(0)} = \{X_k \forall k \in [1, K/2]\}\) and \(S^{(1)} = \{X_k \forall k \in [K/2 + 1, K]\}\) and run these in parallel. One can observe that these two subsets are now each others complementary space \(S_{[k]}\) and, therefore, we evolve the walkers in \(S^{(0)}\) only by positions in \(S^{(1)}\) (and vice versa) using the stretch move discussed above. Each walker in subset \(S^{(0)}\) can now be evolved independent of the others in that subset.
Even though the autocorrelation time does not improve significantly compared to the regular stretch move, by using this method we unlock generic parallelization, allowing for multi-threading and distributed computing, which makes this method especially applicable for modern hardware architectures.
References
Budd, T. 2024, Monte Carlo Techniques
Goodman, J. & Weare, J. 2010, Communications in Applied Mathematics and Computational Science, 5, 65